作者:李卓,焦绍赫,张雄峰,管成伟,张超群,夏昊,邱萍相关单位:1.江西省烟草科学研究所;2.江西省吉安市烟草公司峡江分公司;3.南昌大学化学化工学院摘要:成功建立了基于近红外光谱和化学计量学方法的江西烤烟产地鉴别模型和定量分析模型。首先收集江西三大烟叶产区(赣州、抚州、吉安)114个烟叶样品的近红外光谱;然后采用连续投影算法(SPA)筛选出关键的波数点进行主成分分析;再将这些波数点用作4种有监督模式识别方法K-最近邻(KNN)、线性判别分析(LDA)、径向基函数-人工神经网络(RBF-ANN)、反传-人工神经网络(BP-ANN)的输入变量,建立了多组烤烟产地鉴别模型,正确率达到96.4%以上;随后构建了基于偏最小二乘回归(PLSR)的定量模型,可以较为准确地预报烤烟样品的总糖、还原糖、总植物碱、总氮含量。
关键词:化学计量学;烤烟;近红外光谱;产区鉴别模型;定量分析
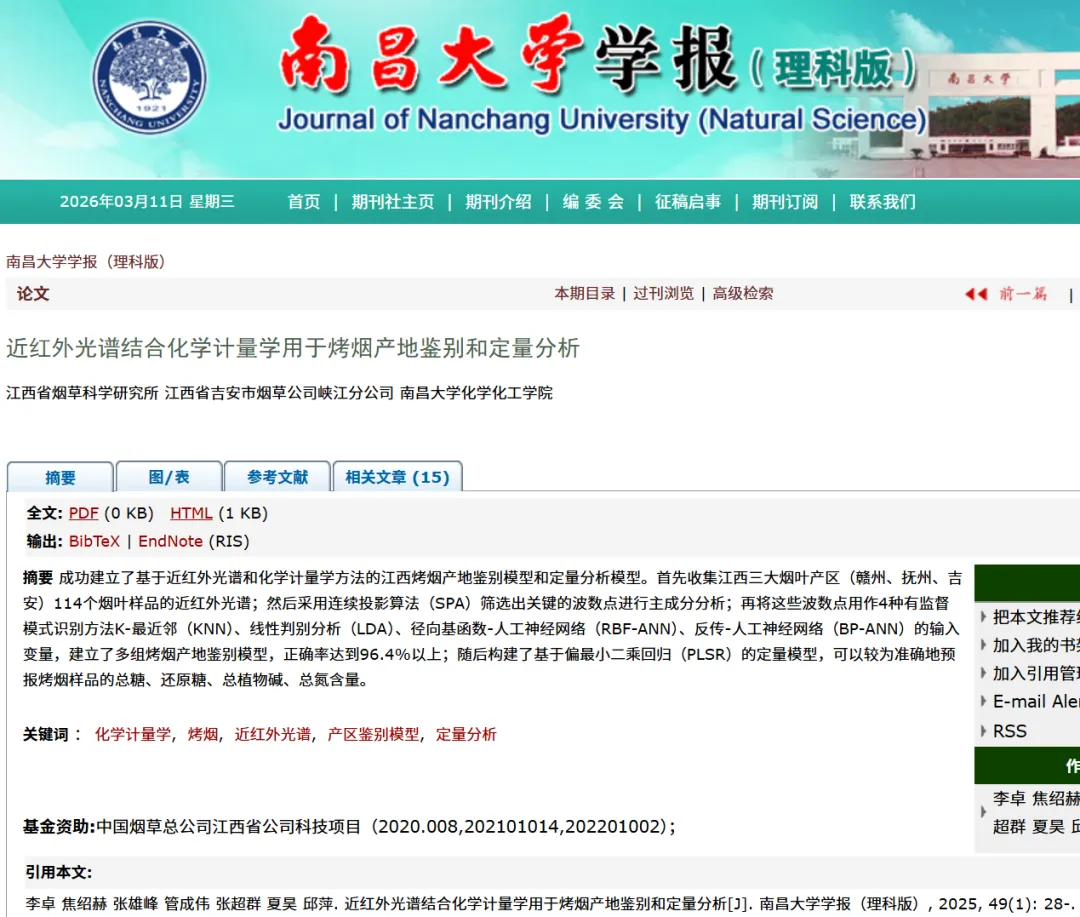
近红外光谱图
图(a)是114个样品的原始近红外光谱图,从图中可以看出,各个样品的光谱图都很相似,很难看出具体的光吸收区别。图(b)是三个产区样品的平均光谱对比,同样高度重叠,表现出高度相似的光吸收谱带,只是相互间存在一些位移,事实上,这种位移并不完全是由于样本间的内在差异引起的,主要是光程差异引起的光谱偏移导致的,具体是在进行粉末样品的近红外漫反射光谱采集时,样品的均匀性和尺寸颗粒不同所引起的。图(c)和(d)分别是采用SNV和MSC进行预处理后的光谱图,可以看出两种方法得到的光谱图十分相似,相比较原始光谱,样品间的光谱差异更小,光谱偏移得到了很大改善,说明两个方法在消除光程误差方面均有不错的效果,只是在纵坐标(强度)上有差异,这源于它们数据处理的原理不同。图(e)和(f)分别是样品的一阶光谱和二阶光谱,可以看出,相比原始光谱,一阶导数光谱的基线差距明显减小并且重叠信息得到了分离和放大,二阶导数在一阶导数光谱的基础上重叠信息得到了进一步的分离和放大,产生了更多的吸收峰,与此同时,噪声也在增大,光谱平滑度明显下降。
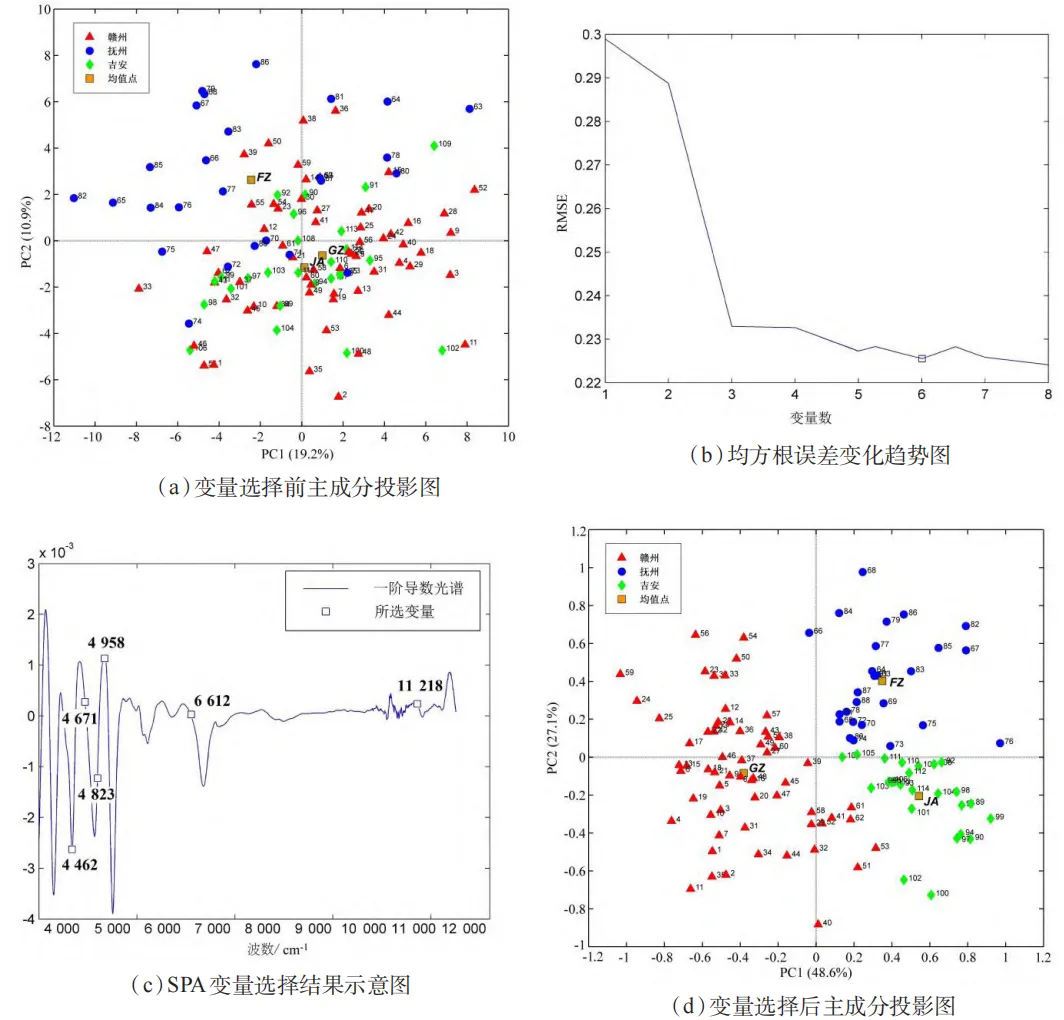
主成分分析投影图和变量选择图
图(a)是将样品的近红外光谱数据先后SNV和求二阶导数后的PCA投影图,可以看出,三个产区的第一主成分(PC1)得分均值比较接近,赣州>吉安>抚州,第二主成分(PC2)得分差别稍大一些,抚州样品PC2得分相对较高,具有一定的区分度,赣州和吉安样品PC2得分均值很接近。图(b)为SPA变量选择过程中RMSEV值随变量个数的变化图,当变量数从1~3时,RMSEV值显著下降,当变量数为6时,均方根误差值基本达到最小并且趋于稳定,为0.22663,因此我们确定了最佳变量数为6,变量数由2127缩减为6个,也极大地简化了数据矩阵和后续运算。图(c)为SPA变量选择结果示意图,清晰的标出了标准光谱中这6个变量对应的波数位置,分别为4462,4671,4823,4958,6612,11218cm-1。4400~5000cm-1的波数范围是变量的主要集中区域,这一区域是长波近红外区,主要承载C-H,O-H,N-H官能团的合频振动信息。选择上述6个变量对114个样品进行PCA,相比较全光谱PCA图,PC1和PC2贡献明显提高,分别为48.6%和27.1%,远高于全光谱的19.2%和10.9%,这表明筛选变量后的主成分分析具有更好的模式识别效果。如图(d)所示,三大产区的样品分类效果得到了明显改善。赣州样品主要集中在二、三象限,在PC1上基本可与另两个产区区分。抚州样品主要集中在一象限,吉安样品主要集中在四象限,两地样品的PC1得分相近,PC2得分有明显区别。三大产区的平均光谱样品也代表性地呈现相同规律。
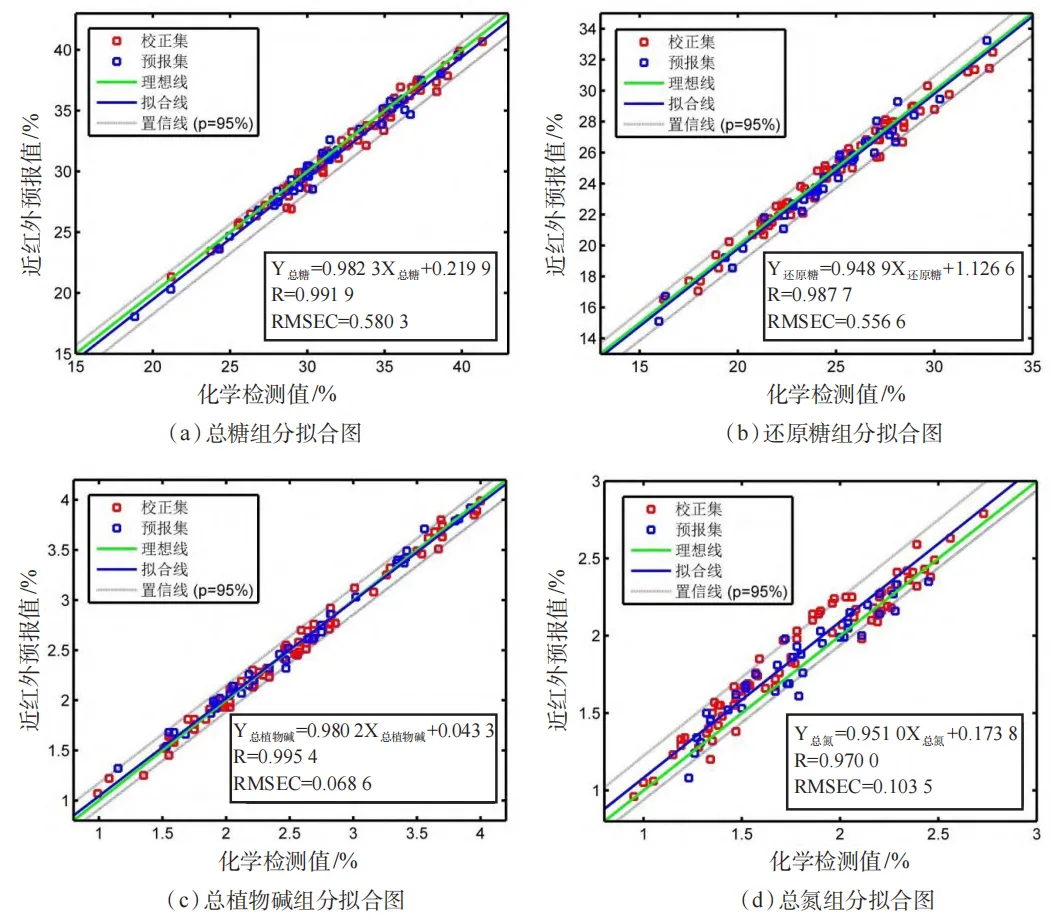
近红外预报值和化学组分测定值拟合图
拟合线和理想线非常接近,拟合效果较好。校正集和预报集的样本分布也很均匀,表明校正集和预报集的样本选择合理。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
