深度伪造检测模型的公平性是其可信部署中的关键问题,尤其在数字身份安全场景下更为重要。现有检测模型往往会对不同人口统计群体,如性别和种族,产生偏置,从而导致系统性误判,并进一步加剧数字鸿沟与社会不平等。与此同时,已有公平性增强方法虽然能够在一定程度上缓解偏置,但通常需要以牺牲检测精度为代价。因此,如何在提升公平性的同时保持检测性能,仍然是深度伪造检测领域亟待解决的重要问题。
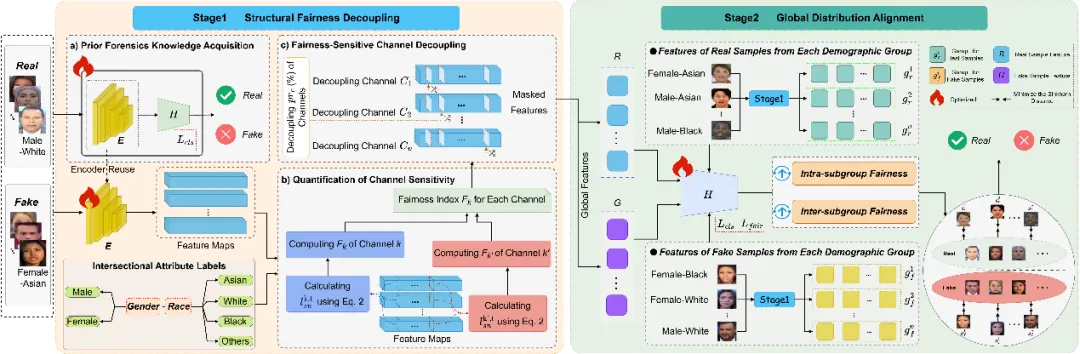
针对上述问题,本文提出了一种双机制协同优化框架,将结构公平解耦与全局分布对齐结合起来。如图1所示,我们提出的方法包含两个阶段:(1)结构公平解耦阶段:首先利用分类损失获取深度伪造检测所需的先验取证知识,保证模型具备基本的真伪判别能力;随后针对模型最后卷积层的各个通道,设计基于类间与类内特征相似性比较的通道敏感性评估准则,并借助软最近邻损失量化每个通道对敏感属性的关联强度。根据计算得到的公平性指数,对最敏感的一部分通道进行解耦,以降低模型对敏感属性线索的依赖。(2)全局分布对齐阶段:在第二阶段,方法从分布层面进一步优化公平性,将每个人口子群体中真实样本与伪造样本的预测分布,分别与全体真实样本和伪造样本的全局分布进行对齐。
图1 所提方法的框架
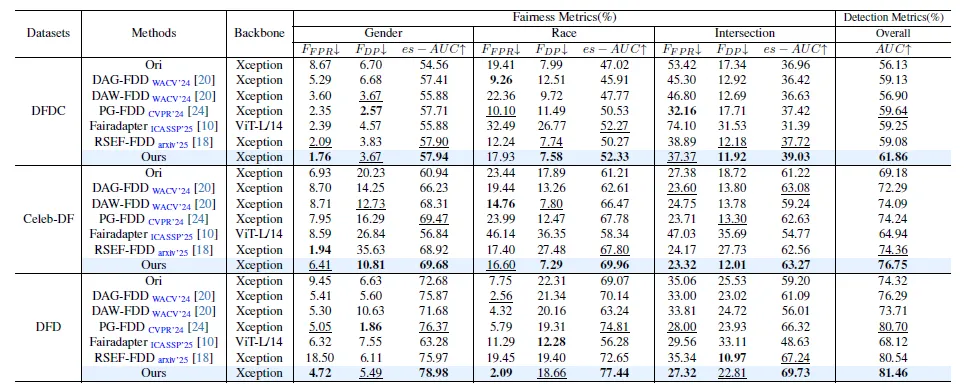
如表1所示,在数据集DFDC、Celeb-DF和DFD上的定量结果表明我们的方法在公平性泛化和检测性能上实现了卓越的综合表现。与Ori及其他公平检测方法相比,我们的方法在绝大多数设置下取得了最优的公平性指标,并同时获得最高的AUC。相比之下,DAG-FDD和DAW-FDD的跨域泛化能力相对有限,部分场景下甚至劣于Ori基线,而PG-FDD和RSEF-FDD虽然在公平性上具有一定竞争力,却往往伴随着检测精度下降。
表1 DFDC、Celeb-DF和DFD数据集上的定量比较
论文信息
相关论文已被计算机视觉领域顶级会议Conference on Computer Vision and Pattern Recognition (CVPR)接收,作者为南昌大学网络空间安全系的丁峰教授、易文辉、周沄鹏、贺希楠、饶泓教授(通讯作者),以及美国普渡大学胡暑教授(通讯作者)。
Feng Ding, Wenhui Yi, Yunpeng Zhou, Xinan He, Hong Rao*, Shu Hu*. Decoupling Bias, Aligning Distributions: Synergistic Fairness Optimization for Deepfake Detection. CVPR 2026.
供稿:肖梦瑶
义务编辑与校对:薛禹良博士